 Sky Blog
Sky Blog


The equitable remedy known as piercing the corporate veil lacks coherence and consistency. No one knows when or why a request to hold shareholders personally liable for a judgment against their corporation might occur. This uncertainty persists despite numerous, comprehensive empirical analyses.
In 2014, Jonathan Macey and Joshua Mitts (“M&M”) published an innovative study that advanced a bold hypothesis: The entire universe of existing veil-piercing opinions can be explained by a taxonomy of just three policy rationales—achieving regulatory/statutory goals, avoiding shareholder fraud/misrepresentation, and/or advancing bankruptcy values. Notably, this taxonomy omits considerations conventionally believed significant, such as inadequate capitalization and failure to observe corporate formalities.
To test this hypothesis, they used automated text analysis, a novel technique at that time. Like “old-fashioned” judicial content analyses (see, e.g., here), M&M manually coded 1,000 opinions to identify those that involved veil-piercing and their rationales. They then used these codings to “train” an algorithmic model—known as naïve Bayes—to predict the outcomes of 8,380 other opinions (which agreed with their manual codings 76.6% of the time). They then analyzed the semantic differences between veil-piercing outcomes and reported results that “correspond precisely” to their hypothesized tripartite taxonomy.
In a new article, we reexamine M&M’s reported results. Like M&M, we manually code 1,000 veil-piercing opinions, but rather than simply retrace their steps, we deploy three algorithmic models:
- a replication of M&M’s naïve Bayes model, trained on our manually coded opinions;
- Claude 3.7 Sonnet, a large language model (“LLM”) unavailable to M&M in 2014, that classifies opinions “blindly”—without access to any manually coded opinions; and
- an XGBoost stacked ensemble model that combines the classification predictions from both the naïve Bayes model and Claude as inputs alongside other textual features.
We obtain the following agreement rates between our models and our manual codings:
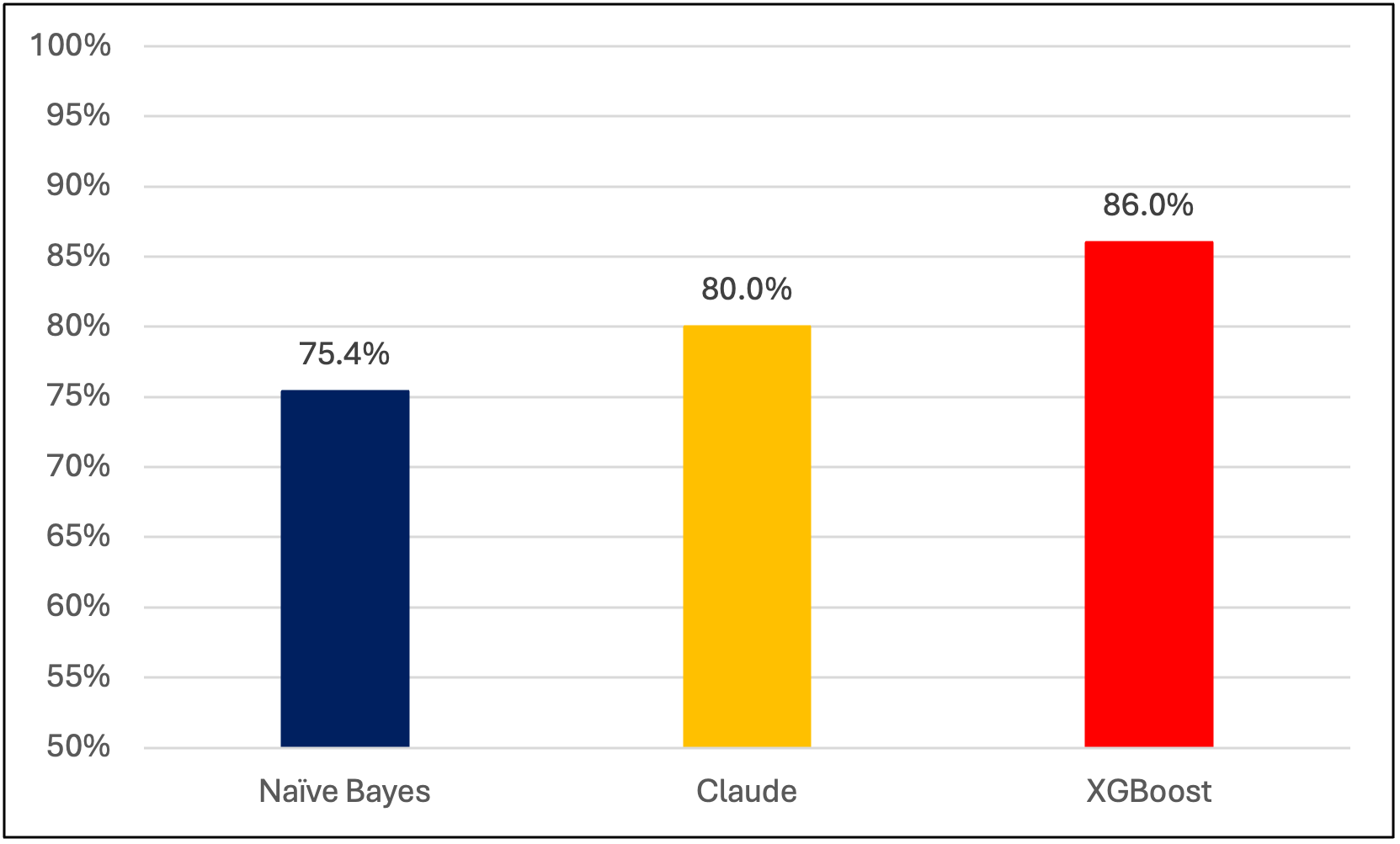
Claude and XGBoost thus outperform not only our replication of M&M’s model, but also their reported agreement rate of 76.6%. We then deploy XGBoost to predict the outcomes of 16,202 other opinions—nearly double M&M’s dataset—and analyze the semantic differences between veil-piercing outcomes.
We obtain statistically significant results that differ from M&M’s in important ways. Specifically, we find Firm Capitalization and Corporate Formalities—which are absent from M&M’s taxonomy—to be important considerations for veil-piercing. Moreover, we find that interactions among words and phrases prove even more important than all of the traditional factors; judicial reasoning operates through nuanced conditional logic on multiple cognitive levels rather than simple factor-weighing. In short, judges appear to be doing something considerably more sophisticated than the prior literature assumed—and it takes modern computational tools to see the pattern.
Another key takeaway is methodological. The performance of Claude and our XGBoost model demonstrate the capacity of LLMs to reliably perform blind judicial content analysis. The conventional way to test reliability is to engage an independent legal expert who independently codes a random sample—typically 10% or 20%—of the same judicial opinions, after which researchers report the rate of agreement between the two coders.
This conventional approach has significant limitations. Finding sufficiently qualified and independent experts is difficult because of the time demanded by manual coding, and the more complex the domain, the more qualified the experts need to be. Even if such experts can be found, agreement between two independent sets of manual codings is not the same thing as accuracy against the ground truth. High agreement rates increase the likelihood that both sets of codings are accurate, but they do not measure that accuracy.
In a companion article, we develop a fully automated alternative. Rather than relying on a single human second-coder for a subsample, we use two independent machine classifiers—Claude Opus 4.5 (making blind classification predictions) and an XGBoost stacked ensemble model—to generate classification predictions for all 1,000 manually coded opinions. Both classifiers apply the same detailed classification approach that governed our manual coding, but they arrive at their predictions through fundamentally different analytical frameworks: Claude through sophisticated natural language understanding of the full text, and XGBoost through a machine learning model that combines textual patterns, the naïve Bayes model’s predictions, and Claude’s predictions.
This automated approach is superior to the traditional method in several respects:
- It covers 100% of the coded sample and so eliminates sampling error entirely.
- It provides Claude’s candid assessment of how strongly the manual coding can be defended and XGBoost’s confidence level, enabling structured estimation of accuracy against an inferred ground truth.
- It is fully replicable, avoiding the variability inherent in relying on a single expert whose judgments cannot be reproduced.
- It produces inferred ground truth classifications for all our manually coded opinions, something that would never emerge from the conventional agreement approach.
By triangulating among the three classifiers and leveraging these additional signals, we estimate that the manual codings achieve approximately 90% accuracy, with errors concentrated in the small subset of cases (8%) where both machine classifiers converge against the manual coding—a pattern that accounts for over 60% of all expected errors. XGBoost achieves an estimated 92% accuracy using Claude Opus 4.5 (or 83% using Claude 3.7 Sonnet). These findings are independently corroborated by a formal maximum-likelihood statistical model that arrives at consistent results: approximately 91% manual coding accuracy and 96% for XGBoost using Claude Opus 4.5 (or 83% using Claude 3.7 Sonnet). The convergence of these two fundamentally different estimation methodologies strengthens the credibility of both.
Taken together, our articles suggest that the conventional wisdom about veil-piercing was not so wrong after all—and that LLMs can serve as powerful tools for empirical legal analysis, capable of performing blind judicial content classification with a degree of accuracy that enables genuine insight into how courts reason.
Douglas C. Barnard is a member of the Dean’s Advisory Council at the Massachusetts Institute of Technology’s (MIT) Schwarzman College of Computing, and Peter B. Oh is W. Edward Sell Fellow and professor of law at the University of Pittsburgh School of Law. This post is based on their recent articles, “The (Large) Language of Veil-Piercing,” available here, and When Humans and Machines Deliberate: Triangulating Toward Ground Truth in Legal Text Classification,” available here.