 Sky Blog
Sky Blog

In November 2019, the Securities and Exchange Commission (“SEC”) issued a notice of proposed rulemaking aimed at the roles played by proxy advisers in providing information and voting recommendations to clients. The move was preceded by substantively similar interpretive guidance used by the SEC in August 2019, which itself attracted strong opposition (including a lawsuit).[1] As a regulatory byproduct of the rulemaking approach, however, the interested persons were afforded the opportunity to submit comment letters to the SEC.
That process ended on the February 3 deadline,[2] with more than 500 comments submitted. While this number is modest compared with certain other notice-and-comment periods,[3] it is reasonably large, given the short time period, and even this number challenges average readers to understand the range of views expressed to the SEC.
What’s the best way to make sense of them? This post offers a helpful tool, in the form of a computational textual analysis of the submitted comments to the proposed rule change. While by no means a substitute for deeper analysis, this type of computational analysis provides a good start to helping make readers more discerning. (Moreover, these approaches can scale quite easily to take on far larger collections of comments.) For anyone interested in reviewing the various metrics mentioned below, a table with detailed information on all comment letters can be accessed here.
The 60,000-Foot View. Comments came in all shapes and sizes, ranging from brief emails to documents that include appendices of more than 100 pages. To focus on core substance, we extracted all of the comments from the SEC’s website, converted them into text format, and stripped out all appendices and annexes. Next, we applied a range of computational techniques that are becoming standard in the field of computational text analysis.[4] Most of the tools used below compare words and short phrases across the population of documents. Documents that use the same words (or phrases) are scored as similar, documents that use different words are considered different.
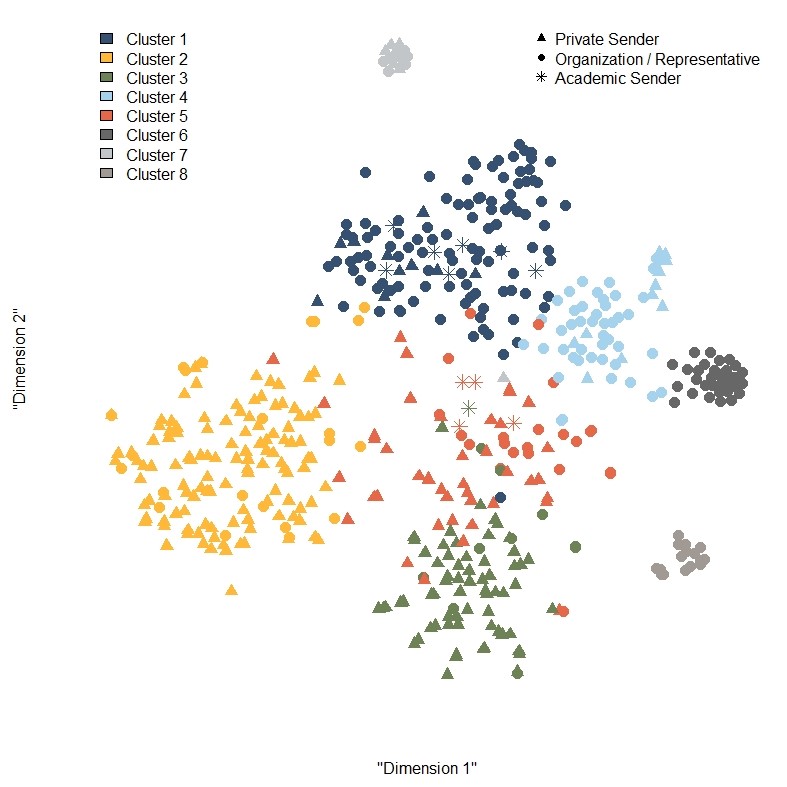
Figure 1: Two-dimensional representation of comments and clusters based on similarity of word usage
A common trick in computational text analysis is to transform complex documents into a low-dimension numerical score. Figure 1 employs this approach to provide an overview of all comments. Documents that are similar to one another will tend to cluster in tight local neighborhoods, and one can see several such clusters in Figure 1.[5] The graphic also differentiates between different senders, subdividing among three groups: (a) private persons (anyone who did not include an institutional affiliation in their sender information), (b) institutional senders (anyone who wrote in their capacity as a member of an organization), and (c) academics (anyone who included the word “professor” in their identifying salutation).
A couple of interesting features of this graphical representation stick out immediately. First, comments by institutional authors (which mostly appear in the upper half of the graph) seem to be qualitatively different from comments by private senders (which mostly appear in the lower half). Second, there are several tight clusters of documents, indicating nearly identical letters. In fact, a simple plagiarism tool indicates that 67 documents (roughly 13 percent) share 50 percent or more of their text with at least one other document. Most of these documents can be found in clusters 6, 7, and 8. On the other hand, 384 documents (around 73 percent) contain language deemed to be at least 90 percent unique, suggesting that a majority of authors produced highly bespoke opinions (rather than relying on a copy-and-paste template).
Figure 2 contains a heat map that conveys more details about the similarity of documents in the various clusters. In this graphic, each document is represented by one row and a corresponding column, and the cells in that row have different colors, depending on the similarity between the document and other documents (which are represented as the columns in this graphic): A yellow cell indicates a high degree of similarity, while blue cells indicate substantial differences. This representation roughly confirms the insights obtained from Figure 1: Clusters 2, 3, and 5 are markedly different from the documents in other clusters. Especially in case of clusters 3 and 5, there is also considerable heterogeneity among the documents within the same cluster.
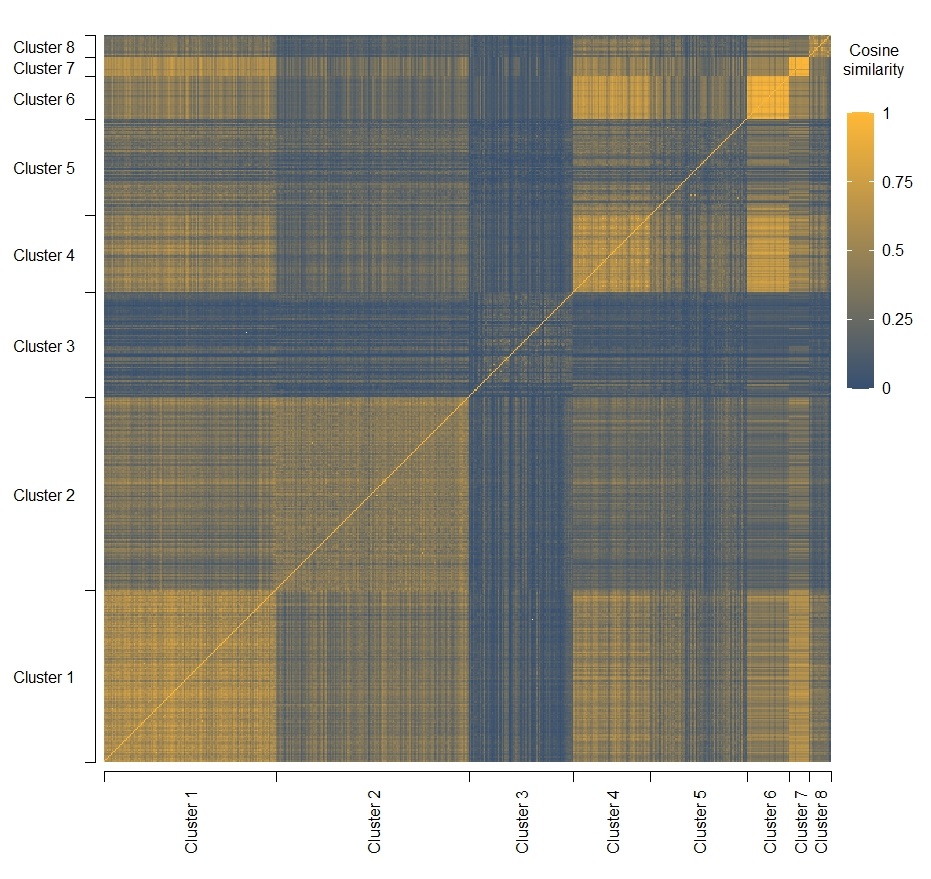
Figure 2: Heat plot based on cosine similarity of word frequencies in documents
Dissecting the Clusters
The numerical similarity (or lack thereof) in the clusters, of course, raises additional questions about what typifies each cluster. Here, a few insights suggest themselves:
Cluster 1: Sophisticated Players
The first cluster, depicted in dark blue in Figure 1, contains comments that one might consider typical of sophisticated organizations and individuals whose professional interests are affected by the rules proposed by the SEC. Most comments in this cluster were written by institutional senders, and the cluster also contains a relatively large share of comments written by academics as well. Comments in this cluster are on average almost 200 percent longer than the average comment in the other clusters, and readability scores indicate that the language of these documents is also fairly complex. The rather technical nature of these comments is also reflected in the characteristic vocabulary of letters in this cluster, which is captured in the word cloud below.[6] By contrast, this vocabulary does not seem to allow for easy inferences about the main thrust of these comments, a finding that is also confirmed by a manual review of a random selection of comments in this group. Of 20 randomly selected documents in this cluster, nine opposed the proposed changes, eight expressed support (although four suggested some modifications), and three expressed neither support nor opposition.

Figure 3: Word cloud of characteristic words for Cluster 1
Cluster 2: Retirement Savers
The second cluster, depicted in yellow in Figure 2, seems to consist largely of documents that are markedly different from most other comments. In fact, many comments in this cluster are written by private persons, and many of these comments address concerns about the impact of the role of proxy advisers on retirement savings, a topic that is also reflected by the typical vocabulary displayed in the word cloud for this cluster. More precisely, many senders describe a politically motivated agenda of proxy advisers, which they perceive as a threat to the financial performance of pension funds. These are the reasons why many letters in this cluster come out in support of the rules proposed by the SEC. This tendency is also reflected by the fact that the language of letters in this clusters is on average more positive than the language in most other clusters.
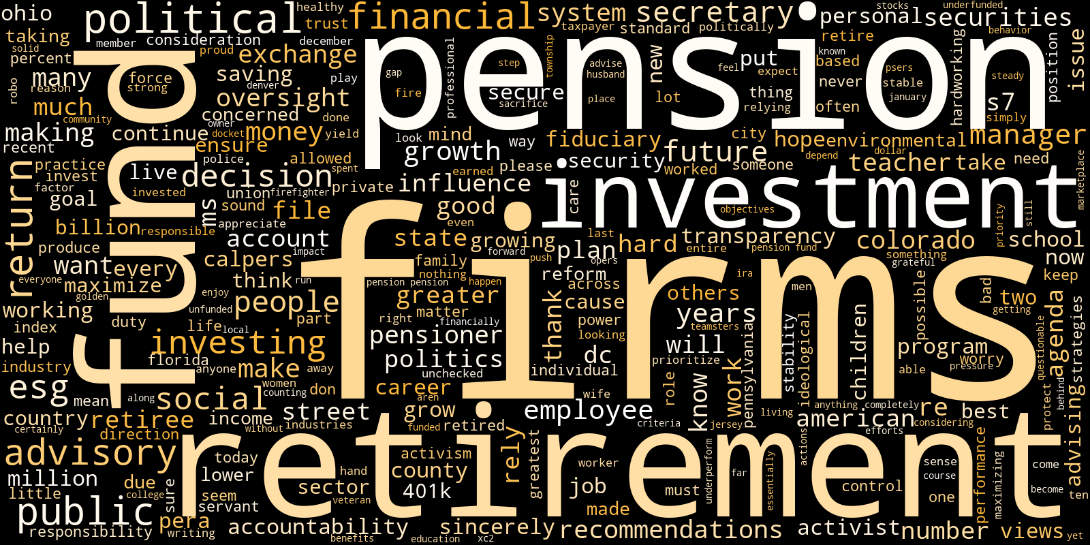
Figure 4: Word cloud of characteristic words for Cluster 2
Cluster 3: Engaged and Concerned Citizens
Like the second cluster, the third cluster also occupies a position further away from other clusters, although the overlap with other clusters is slightly more pronounced than in the case of Cluster 2. Also similar to the second cluster, the third cluster consists mostly of letters written by private persons. These documents are on average shorter than the documents in any other cluster, with most documents not longer than a paragraph. As can be seen from the word cloud, the typical language in this cluster is rather nontechnical, with many senders basing their support of the proposal on general views about the world, be they political or otherwise. God is mentioned more often than in other comments, and so is President Trump.

Figure 5: Word cloud of characteristic words for Cluster 3
Cluster 4: Financial Professionals
The fourth cluster consists mostly of letters written by investors and investment managers. Letters in this group mostly oppose the proposed rules as limiting the possibilities of shareholders to influence the decisions of corporations. This is reflected in the vocabulary typical of letters in this cluster, which contains a number of words related to shareholder engagement.
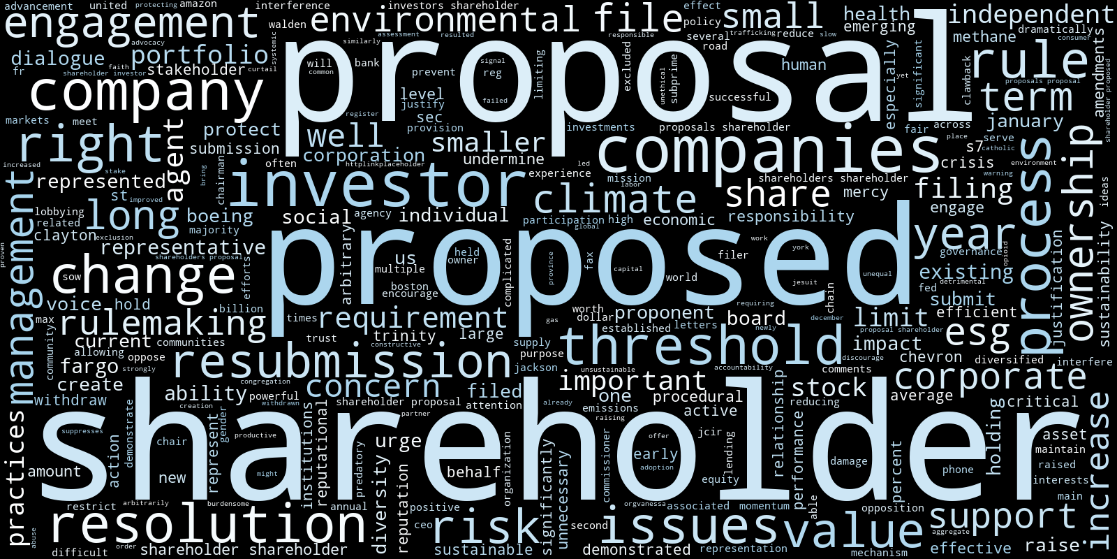
Figure 6: Word cloud of characteristic words for Cluster 4
Cluster 5: Mavericks
Cluster 5 contains a broad range of different types of letters that do not fit neatly into an easy-to-describe box (in contrast to the clusters described above). Letters in this cluster tend to focus on specific features of the proposed rules (rather than broad pronouncements); beyond that, they are heterogeneous in other ways. For example, while the majority of letters in this cluster oppose the proposed rules, others offer support. And, at least in comparison with clusters 1 and 4, the language deployed in this category of letters tends to be somewhat less technical: Several measures of readability show that these letters are substantially less complex than letters in these clusters. Indeed, many letters in Cluster 5 mention the personal experiences of the author alongside more technical arguments about the merits of the proposed regulation.
Figure 7: Word cloud of characteristic words for Cluster 5
Clusters 6, 7, and 8
As noted above, each of these clusters manifests considerable within-group similarities, indicating that the constituent letters either come from common templates or deal with a rather narrow set of issues.
Letters in Cluster 6 are similar to letters in Cluster 4 in that they opposed the proposed rules on the basis that they would interfere with shareholders’ ability to influence corporate decisions; also, most of the authors of these letters are small investors or investment managers. What distinguishes these letters is that they are at least in part the same. Most if not all state that “the shareholder proposal process has served to benefit issuers and proponents alike as an effective, efficient and valuable tool for corporate management and boards to gain a better understanding of shareholder priorities and concerns,” and they argue that “the proposed increase in ownership thresholds will make it difficult for smaller investors to voice important concerns and raise issues of risk to the companies they own.”
Letters in Cluster 7 similarly share some of their text, and they also oppose the proposed rules. For example, text that can be found in most of these letters maintains that the proposal “fosters an inappropriate pro-management bias in proxy advisor reports,” which makes it harder for investment advisers to “meet their fiduciary responsibilities.”
Cluster 8 consists of letters asking the SEC to extend the comment period.
Identifying Unique Comment Letters
The analysis above conveyed general information about the different types of letters submitted to the SEC, and the relative size of each group of letters. In this section, we focus on a different challenge: unique viewpoints. While letters copied from a template offer nearly identical views (by definition), unique documents are more likely to convey a range of opinions. Although a rough proxy of uniqueness can be inferred at the cluster level (e.g., via Figure 2), is it possible to identify more precisely those letters that communicate unique ideas and views to the SEC?[7]
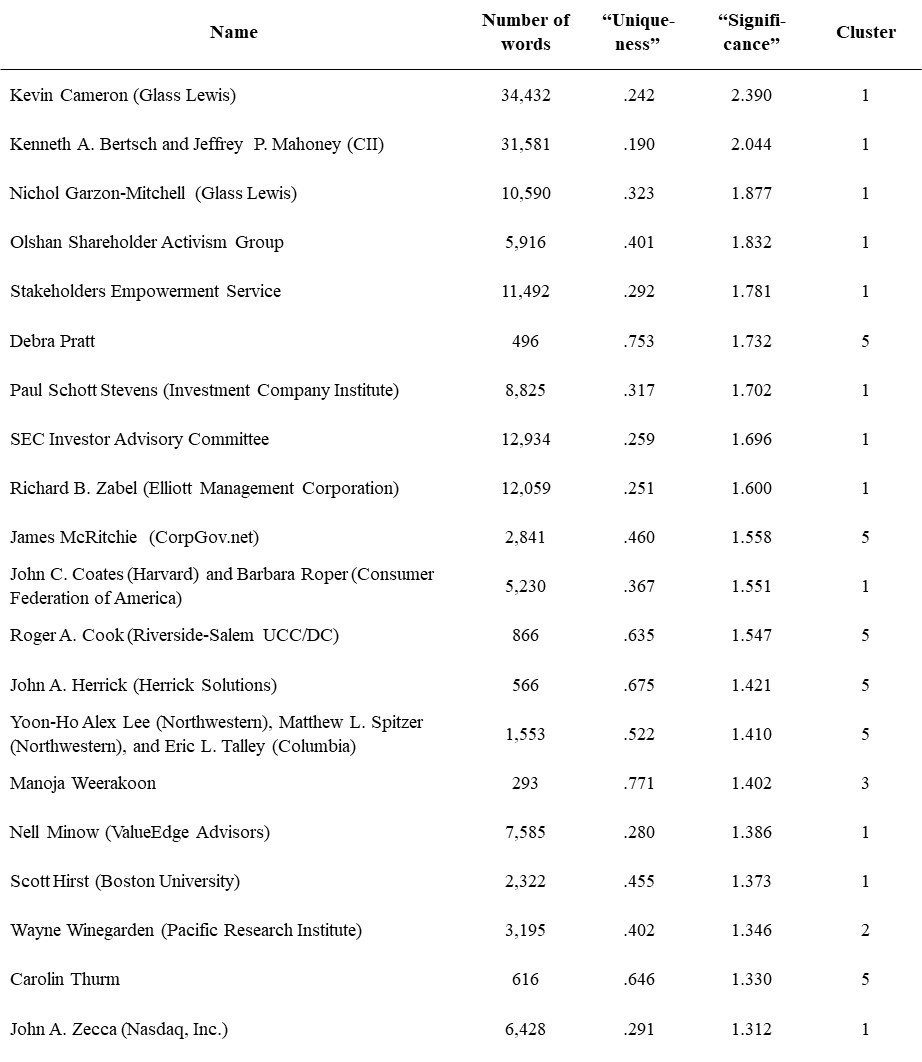
It turns out that there is. One helpful approach for doing so is to use a metric that combines information about the length of a letter with information about the uniqueness of the vocabulary in the letter. More precisely, the measure is based on the logarithmic value of the number of words in a letter as well as 1 minus the average distance (measured as cosine similarity) from the 25 comments that are most similar to a letter. The “significance score” is derived by calculating the sum of the normalized value of both measures. Table 1 reports the leading 20 comment letters in this category.[8]
Conclusion
The recent publication of the SEC’s proposal to change rules governing proxy advisers has triggered a substantial number of comments, and the SEC as well as interested observers now face the challenge of making sense of these large swaths of text. This post demonstrates how computational techniques can be leveraged to gain insights into the text of comments under such circumstances.
In the case of the regulatory proposals at hand, a number of interesting patterns emerge. First, comments are roughly equally divided between support and opposition: Letters in clusters 2 and 3 mostly support the reforms, while letters in clusters 4, 6, and 7 mostly oppose them. Clusters 1 and 5 do not clearly show either support or opposition. While letters in these clusters are roughly evenly split between both camps, some also focus on providing the SEC with additional information, essentially refusing to take a clear stance on the proposed rules. Second, different types of senders tend to support different positions. In line with predictions at the time the proposal was released,[9] most small investors and investment advisers oppose the proposed rules. By contrast, the rules receive the most support from individuals, many of whom claim that the rules serve a political agenda of investment advisers.
Table 1: Top 20 Significance Scores
ENDNOTES
[1] Council of Institutional Investors, CII Fact Sheet on Proxy Advisory Firms and Shareholder Proposals, https://www.cii.org/files/about_us/press_releases/2019/11-05-19%20CII%20Fact%20Sheet%20on%20Proxy%20Advisory%20Firms%20and%20Shareholder%20Proposals.pdf (accessed February 23, 2020).
[2] The deadline for submitting comments expired on February 3, 2020.
[3] Gautam Nagesh, Federal Agencies Are Flooded by Comments on New Rules, Wall. St. J. (Sep. 3, 2014), https://www.wsj.com/articles/federal-agencies-are-flooded-by-comments-on-new-rules-1409786480 (accessed February 2, 2020).
[4] See, for example, Michael A. Livermore and Daniel N. Rockmore, Law as Data: Computation, Text, and the Future of Legal Analysis, Santa Fe, NM: Santa Fe Institute Press 2019. See also Michael A. Livermore et. al, Computationally Assisted Regulatory Participation, 93 Notre Dame L. Rev. 977 (2018) (exploring ways in which agencies can leverage similar tools in the face of large numbers of comments to proposed regulation).
[5] For nebbishes looking to nerd out on the technical details, comment letters are represented by vectors based on the frequency distributions of words. I first applied a “term-frequency-inverse document frequency” (or TF-IDF) transformation common in information retrieval to the frequency distributions. That representation of the documents was then reduced to 50 dimensions by applying the truncated SVD algorithm. Finally, I employed the TSNE algorithm to reduce dimensions from 50 down to two. Clusters were computed with the K-Means algorithm.
[6] Words in the different word clouds are selected based on the difference between the relative frequency of these words in documents in the cluster as compared with other documents.
[7] Livermore et. al (supra note 7) discuss this problem as the “needle in the haystack problem” and report on a measure for the “gravitas” of a comment.
[8] Note that two comments were manually removed from this list because the uniqueness of the letter was entirely driven by words unrelated to the main contents of the texts (for example, the names of signatories of the letter).
[9] Nicolas Grabar et al, Proxy Advisory Firms—The SEC Drops the Other Shoe, Harvard Law School Forum on Corporate Governance, November 25, 2019, https://corpgov.law.harvard.edu/2019/11/25/proxy-advisory-firms-the-sec-drops-the-other-shoe/ (accessed on February 23, 2020).
This post comes to us from Jens Frankenreiter, postdoctoral fellow in empirical law and economics at the Ira M. Millstein Center for Global Markets and Corporate Ownership, Columbia Law School.